A lot of k8s projects have pull=always which quickly makes you reach your ratelimits if any issuers occur. Harbor has a nice proxy cache feature to help with this
Go to the web UI with admin:Harbor12345 and set up an endpoint for dockerhub. Then, create a project and link it to that dockerhub endpoint. Do not forget to change the password for the admin user!
Since i had little prior experience with K8S, this document serves as a sort of self-documentation of setting up opendesk, a sovereign office suite. While it might be nice to use ArgoCD for such a setup in production, I have no experience with that *yet*.
This is not a full tutorial. Just a reference for your own install and it may have some things out of order!
Ensure you have enough CPU cores and RAM or opendesk will fail to install
I chose kubeadm as it seems to be a bit more production-oriented than minikube. Interestingly, i found the cri-o site to be the best source for information regarding K8S installation. Cri-o is a container runtime for Kubernetes similar to containerd. I will be using ubuntu 24.04 as the base.
We install ingress-nginx, which i believe is going out of support but is the only currently supported ingress controller for opendesk
# This may be outdated. Take care!
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
helm install quickstart ingress-nginx/ingress-nginx --set controller.config.annotations-risk-level=Critical --set controller.config.strict-validate-path-type=false --set controller.allowSnippetAnnotations=true
--set controller.admissionWebhooks.allowSnippetAnnotations=true
# -f values.yaml
# You may or may not need this values.yaml:
controller:
# service:
# type: "NodePort"
hostPort:
enabled: true
service:
type: "ClusterIP"
config:
annotations-risk-level: "Critical"
strict-validate-path-type: "false"
allowSnippetAnnotations: true
admissionWebhooks:
allowSnippetAnnotations: true
Storage
The local path provisioner does not work for opendesk as it needs the sticky bit. Use Longhorn!
# longhorn-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: longhorn-ingress
namespace: longhorn-system
annotations:
# type of authentication
nginx.ingress.kubernetes.io/auth-type: basic
# prevent the controller from redirecting (308) to HTTPS
nginx.ingress.kubernetes.io/ssl-redirect: 'false'
# name of the secret that contains the user/password definitions
nginx.ingress.kubernetes.io/auth-secret: basic-auth
# message to display with an appropriate context why the authentication is required
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required '
# custom max body size for file uploading like backing image uploading
nginx.ingress.kubernetes.io/proxy-body-size: 10000m
spec:
ingressClassName: nginx
rules:
- http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: longhorn-frontend
port:
number: 80
Now go to the longhorn web UI to check! Under settings, set the default replica count to 1 and minimum number of backingimage copies to 1 aswell if running single-node. You might have to do this after the opendesk install in the UI aswell since it doesnt seem to follow the defaults.
Certificates
Use cert-manager with Nginx
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.1/cert-manager.yaml
kubectl create --edit -f https://raw.githubusercontent.com/cert-manager/website/master/content/docs/tutorials/acme/example/production-issuer.yaml # Change Issuer to ClusterIssuer and remove the namespace
Loadbalancer
I chose metalLB, though this has caused some issues. Can’t flannel help here?
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.15.2/config/manifests/metallb-native.yaml
kubectl apply -f pool.yml # you need the file below
kubectl apply -f adv.yml # See below
# pool.yml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- 45.136.141.166-45.136.141.168
- 45.136.141.154-45.136.141.156 # I don't think you need this many IPs
#adv.yml
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: example
namespace: metallb-system
Install Opendesk
# Update with the newest version
wget https://gitlab.opencode.de/bmi/opendesk/deployment/opendesk/-/archive/v1.10.0/opendesk-v1.10.0.zip
unzip opendesk-v1.10.0.zip
kubectl create namespace opendesk
kubectl config set-context --current --namespace opendesk
Now, configure and start!
First of all, have you setup all required DNS settings?
This post intends to be a quick introduction to some negotiation basics. It was mostly written for myself, but may be of use to others
Most importantly, negotiation is often not just about getting something for the lowest price. You will have the most success if you are able to find value for both parties.
1. Agenda
In order to get what you want, you either want to be the one leading the negotiation, or at least an equal. This does absolutely not mean that you should talk too much!
You should try to match the counterparty’s people count. If they come with two then you come with two. There should be at least one person taking notes. Some people prefer to have two sets of notes: one general to be sent to the counterparty and one private.
If viable in your situation, prepare a short agenda: – Opening (who, what) – Getting everyone up to date if necessary – Negotiation – Closing, hand shaking
2. Preparation
Preparation is 80% of the negotiation.
It is EXTREMELY important to have as much information as possible about the thing you are negotiating, and who your opponent is. This is triple as important when you have multiple people on your ‘side’, as disagreement during the meeting can be fatal. Some questions that may help:
What do i want from this negotiation: What exactly do I want
How do my interests rank in importance: Very important. Many people have the tendency to want either a lot of things, or too little. Have some interests, but it may be worth to have some interests that you would easily give away. Be very clear on this ranking with your team.
What are my strengths? What can i offer that others can’t. Why does the other person need me specifically.
What are my weaknesses What can be used against me. Where am i less good of a choice than others, what am i missing
What do i have that the other party needs If not, don’t worry yet if you are able to realize it on a short term. If you have no chance of offering what the other party needs, do not lead them on and ruin your reputation. Keep in mind that what they say they want and what they need may differ.
What is each party’s BATNA Best Alternative To a Negotiated Agreement. If you can’t reach a conclusion, what backup do you have?. This is a huge factor in how hard you can push and what terms you can set. You should not be scared to walk away from a negotiation if you get a bad offer. A bad deal will hurt you more in the long run. You may be able to get called back after walking away once, but don’t expect this to happen.
Do not reveal your batna right from the start, but for example when you see that you have reached an impasse. BATNA can also be a great form of leverage. Do not use it badly, but instead frame it as helping find a good outcome. DO NOT BLUFF, this will almost always end up hurting you. Position it as an oppertunity for a win-win outcome.
Stay flexible and open to negotiation. Be willing to slightly adjust. Prepare for counteroffers or to explain/explore the gap. Evaluate the response to your BATNA
How high do i want to anchor Anchoring is a magic trick that any good negotiator will use. Keep in mind the counterparty will also likely use this against you. Anchoring means taking the Highest price the counterparty would likely accept, and add 30% to that. Humans have the tendency to make things relative, and now you pushed the average in your negotiation discussion up to a more preferred range for you.
In what way can i make a good deal for both parties? (increase the pie) You usually have more to negotiate on than just money. What can you do to offer more value to the other party? You can often increase the value of a deal by more than it’s monetary cost.
What’s your ZOPA Zone of possible agreement. Both parties have a rough minimum and maximum price range. The ZOPA is the range where this overlaps. ZOPA’s can move a bit depending on what additional value is offered, but be aware that you shouldn’t move it too much for it to become a bad deal. While you may give rough hints about your ZOPA when you are not moving in your negotiation, you should never give clear limits.
You might also see the term Reservation Point, which is the point in the negotiation where a deal is no longer profitable to you.
What’s your information It’s very important to have as much information as possible: What are we talking about, how’s the market. If your counterparty sees you do not know what you are talking about, this will cost you dearly. Make sure that information is equal between team members.
Who are you up against Hierarchy of goals. The person who you are talking to may have different KPI’s than the company, or than the final person deciding.
Recognize if your countertparty is a hard negotiator. You can usually already see this from their title and years of experience, but be ready to adjust this during the negotiation.
3. During
If the counterparty comes to your ‘home base’, see if you can have some smalltalk beforehand. Offer them a coffee. Reciprocity is persuasion 101.
Some tips: Watch your and the counterparty’s emotions. Become very aware of nonverbal communication of your counterparty, but also your own. Do not fiddle, sit upright take active notes if possible.
Prefer in-person meetings over online, as a lot of nonverbal information gets lost.
Look dependable. Humans hate one thing the most: risk. If you seem like a person they can depend on, you already take away half of their problems.
Ask questions! Every question makes your counterparty give away more information that you can use against them or to create more value!
You are *hopefully* well prepared. Make the best of it!
4. Ending
Independent of if you come to an agreement, stay friendly. You may have to talk to this counterparty again, and a friendly party will get way better deals in the future.
Importantly: talk about next steps and rough timeframes. This will make a clear path forward to round off the deal.
5. After
Todo: Finish this post
Send the counterparty notes, plan a new meeting to look at progress. Look proactive, friendly. You will hopefully deal with them more often!
We all know we should have backups, but you often see ransomware groups also targeting backup storage. Luckily, there are some nice ways to make your backups-over-SSH more secure using a neat authorized_keys trick.
In short: You can add some options to your authorized_keys file to force connections with that key to run a specific command.
These tricks should also work on Hetzner storage boxes, and most other providers that allow you to upload an authorized_keys file.
Borg (non-immutable)
At Ferox, we use the following for onsite quick-access borg backups:
Since borg works over ssh, it tries to run borg serve on the remote host. This command basically replaces that borg serve command with one that is limited to a specific folder.
Borg (Immutable)
Keep in mind that this key will now not allow pruning or deleting backups, so you will have to schedule that from a trusted location/key.
The difference between a good webdev and a great one is that the great one can not just make sites, but also reason about ways to get more sales. I will mainly be focussing on hosting and IT websites because that is my area of expertise, but you will see these things everywhere. I plan on writing another article on business models, writing, and maybe talks. But i’ll see how far i can get.
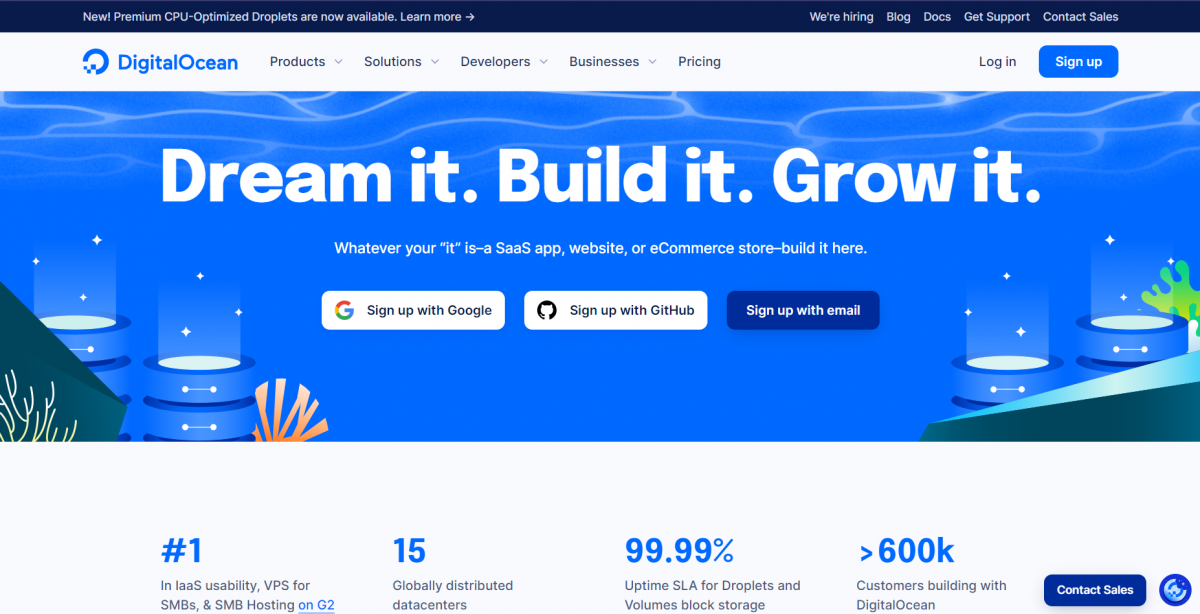
Example: DigitalOcean
Digitalocean is one of those sites that every web developer should have looked at. I’ll point out a few things that they do right, in no particular order:
Colors and design stick out. The blue sticks out, and together with the modern design makes for a pleasant page to look at.
The subtitle instantly shows some examples of their most common customers, and is kept very generic. People who want to host an application that fits one of these categories is immediately ensured that they’ve come to the right place.
One-click sign-on with the two platforms that are most commonly used (and ofcourse a normal email signup). The barrier of entry is very low.
Sales button on the bottom right for questions, and bigger businesses that may need more convincing but bring in more value.
The numbers at the bottom of the page show that this is no small company and can probably be trusted.
Some other things done well on the DO website from a business perspective:
Case study – While i would argue that these are not very useful for most people, they absolutely help in convincing other people that a similar business is already using them and thus it should be good.
Free credits. The cloud hosting market is competitive but with limited-time free credits people can start deploying their app without any risk, and will likely stay if it just works.
Digitalocean has a very large knowledgebase of non-do related help articles for almost anything related to system administration. This helps both their marketing with increased brand awareness and gives an enormous boost to their SEO.
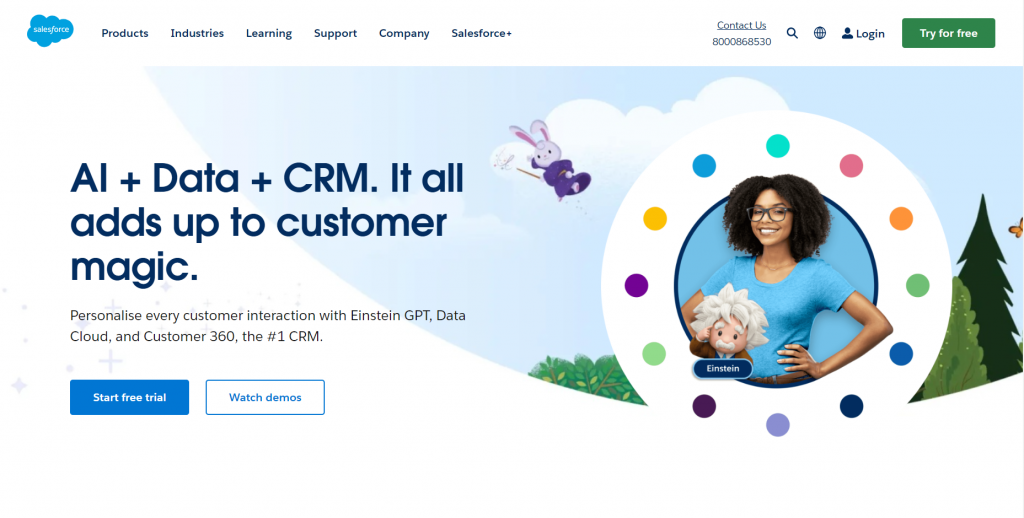
Salesforce is a b2b CRM company. While i do not enjoy their design so much, they got a lot right in regards to selling.
2 big buzzwords and their product type, right as the first thing you see. This site is obviously more targetted towards business decision makes and will immediately get them interested.
They offer a free trial, and a demo video so you can get in without any excuses.
The header also contains a “industries” button where they lay out how different industries use their product. This gives them a sense of having experience and shows examples of how your company can be improved by their product.
Also; a plain old phone number. Pick up the phone and you’re right there talking to their sales team. They also offer a livechat, but it’s a bit more hidden for some reason.
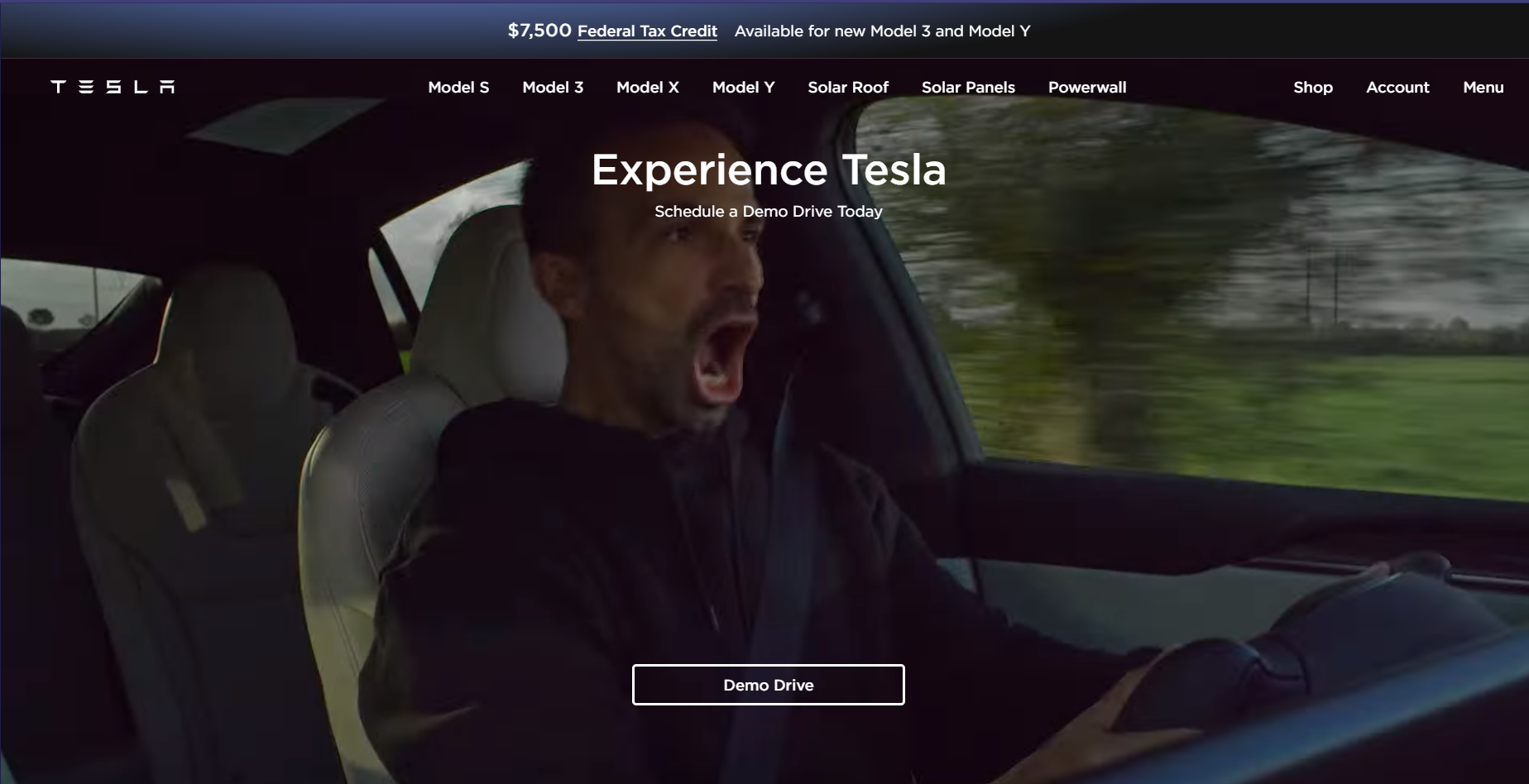
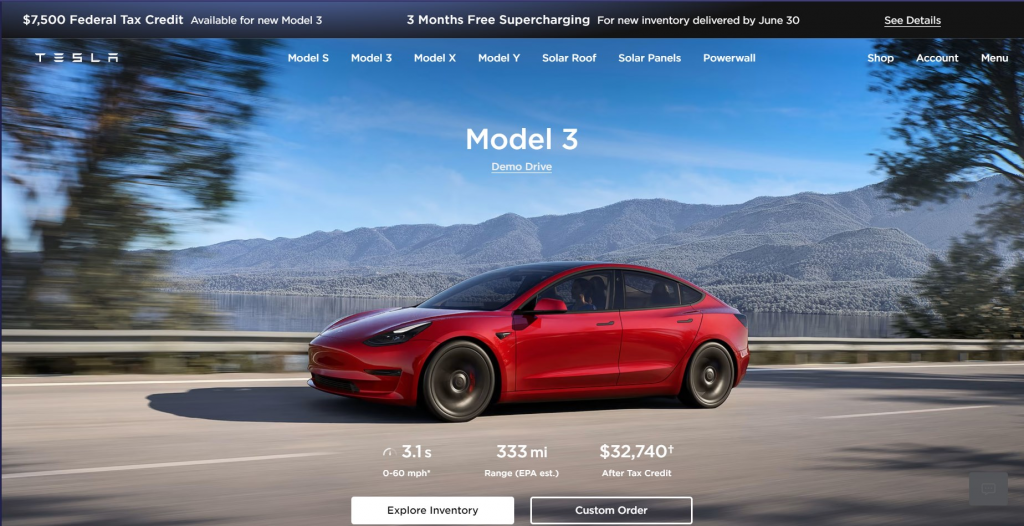
While the salesforce site was relatively plain, the tesla website again sticks out. You are instantly dropped into a video of a tesla car driving through harsh conditions and a man enjoying the speed – probably recognizable for their target audience.
They put a lot of attention into getting a demo drive. I presume because their cars are mostly sold from their website so that the usual demo drive at the dealer is less of a thing.
One thing that sticks out is the big 7500$ tax credit banner. People *love* free money and this makes it feel like it is both time-bound and a very good deal, even though teslas are quite expensive.
The product page is also something different. You instantly see the car in a nice view, the most important stats and the option to choose a predetermined model or custom order (on a consumer car?! what?!)
Some of the most common concerns are also instantly addressed on the product page. An image shows the safety structure of the car (americans…), the thousands of charging stations and a visualization of the range
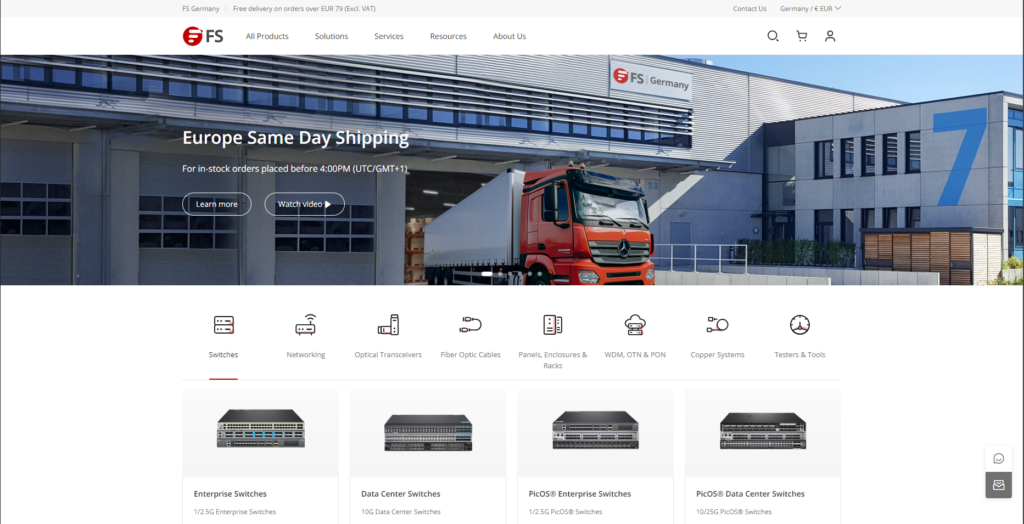
FS sells network supplies to businesses, and you can instantly recognize a few points
Europe Same Day Shipping. This is often an issue in the b2b space. And takes away an important doubt.
I’m visiting from Europe, so i get European page. FS is mostly chinese, but seeming local really helps.
All products prominently visible
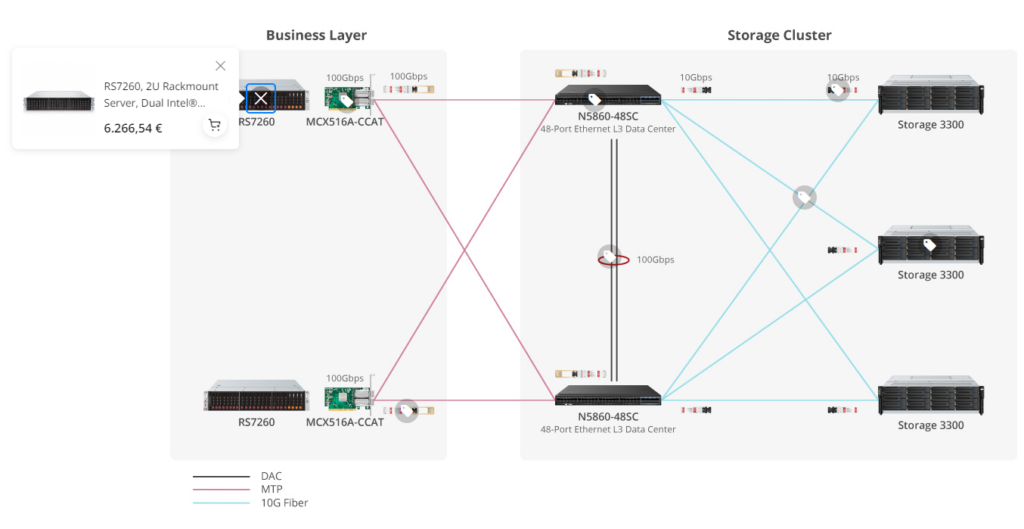
Showcases like this is why i wanted to show this example. Showing an example layout talking about possible setups is an *Amazing* way to get more people to buy more product. Not everyone is an expert, and having a setup that is almost copypastable is great.
Godaddy
Alright, let’s try it for yourself. What design and business choices can you pick out from this website?
There are many good other examples of well-executed websites, but showing more would mean a lot of repetition of the previous examples. Do you have site that you really like or has some novel ideas? let me know and i might add it to the article.
Some notes and explanations for crypto. Title is a joke reference to crypto guide titles often containing the word “made Simple”, or “Gentle introduction”.
prereqs: modulo function (remainder in division) XOR function (2 bits are the same: 0, 2 bits are different: 1)
Terminology Ciphertext: Encrypted text, should not give any information about the plaintext. Plaintext: The original (secret) message. We want to share this without anyone else being able to eavesdrop. Key: Secret “password”. This is used to encrypt and/or decrypt messages. Bruteforce: Dumbly trying all possible combinations/keys. Initialization vector: Initial starting value when doing chained block encryption.
Secret-key/Symetric crypto
Secret-key crypto is the simplest form of encryption. You can use the same key for encryption and decryption. A very simple usable function is the XOR function. This is also called the One time pad or Vernam cipher.
In case of the one-time-pad/xor, One must be very sure to not encrypt two messages with the same key k as that would make an attacker able to derive the original messages by XOR’ing the two ciphertexts
Secret key crypto is hard to use because the key has to be shared between the two parties, without anyone else being having access to it. This is even more cumbersome if the key has to be different for every message sent. You also have to have a secret key shared with every person that you want to communicate with which will mean 0.5 * N * (N-1) keys for N people, which will very, very, very quickly add up.
Public key/Asymetric crypto
Public key cryptography solves this problem by having two types of keys. A public and a private key. The public key can be safely published for anyone to see and the private key is kept only by you. Anyone can encrypt a message with your public key but only you can decrypt it with your private key.
A good way of explaining this to a non-cryptographer is the example where the public key is a lock that you can send to anyone, but only you have the key to. Anyone that wants to send you a message can request a lock (public key) from you, lock it. And then send the locked crate with a secret message knowing that only you can unlock it. An attacker getting their hands on a lock is not a big deal, but getting the key to all the locks is.
Cipher functions (caesar,substitution)
A small step back to the olden days. You might have heard of the caesar cipher where any character is replaced by another character N places further. This N is the key and posession of this N allows for decrypting the message. This decryption was hard when it had to be done by hand but now with computers it is trivial to bruteforce. The class of cipher functions that the the above c’s cipher belongs to is called substitution ciphers. (Simply replacing a character by another according to simple rules)
Stream cipher
A stream cipher is a more generic name for encryption that happens bit-by-bit, take for example XOR’ing with a key that is just repeated over and over. This can end up being relatively slow for larger data sizes.
Block Cipher
Generally an improvement to stream ciphers is to instead use fixed-size blocks. This often means that we have to add some padding to the content to fit the total block size.
The plaintext is split up into parts of block-size b, where if needed this is extended to not have any half-full blocks. (generally with 1000… or 0000..)
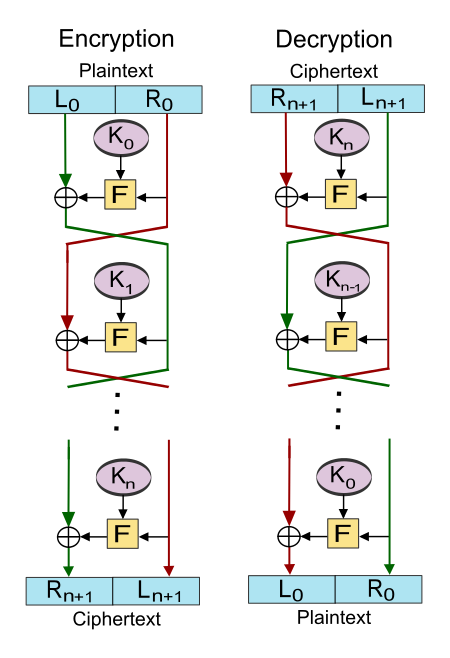
Feistel cipher structure
The Feistel cipher is a structure used in for example the old (and unsafe) encryption standard DES. Many modern ciphers are based on the Feistel structure.
Shamelessly stolen from wikipedia
The feistel cipher works by having multiple rounds, where for each round a different (sub)key is used (K0 – Kn). The input is split into two equal parts (Left and Right). Then the encryption function is ran over R0 with Key k0, the result of which is XOR’d with the left plaintext. Then left and right are switched around for the next round. Given enough (even 3-4) rounds the cipher is already a pseudorandom permutation
More info on the wikipedia page, But this is not very important for the basics of cryptography.
Feistel ciphers have a very cool property: If you swap the ciphertext and throw it in the place where the plaintext is normaly put in, it will output the plaintext. Even if F is a hashing function, then it will still be able to decrypt it. This works because the XOR operation is always reversible.
Modes of operation
There are multiple ways to structure the encryption steps of multiple blocks. Here are a couple of the simplest ones, but they might not all be secure. All the methods talked about here are about Symetric-key encryption. (same key for encrypt and decrypt)
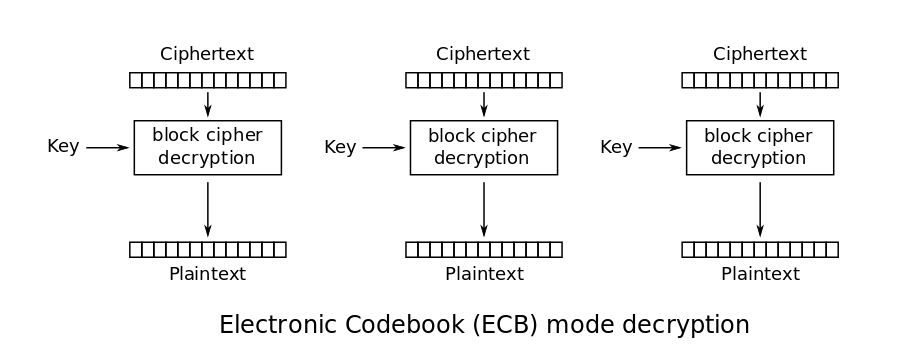
ECB
src: Wikipediasrc: wikipedia
Ecb is perhaps the simplest mode of operation, every block is encrypted on its own without any input from other blocks. While this is simple and is good if you don’t want single-bit errors in encrypted blocks to propagate, it is possible to view the old data.
Tux, the cute linux pinguin
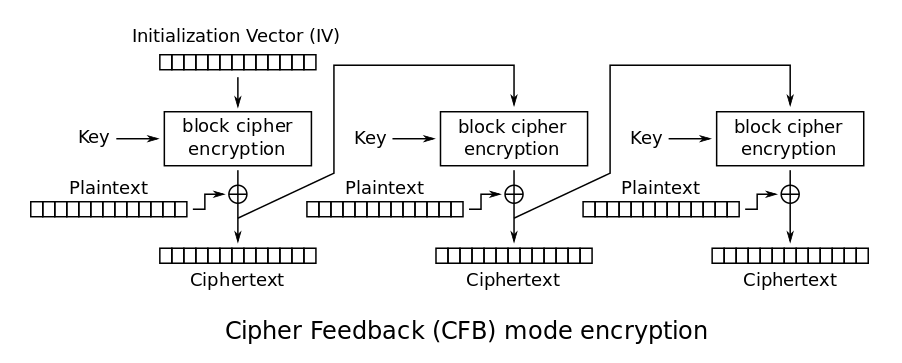
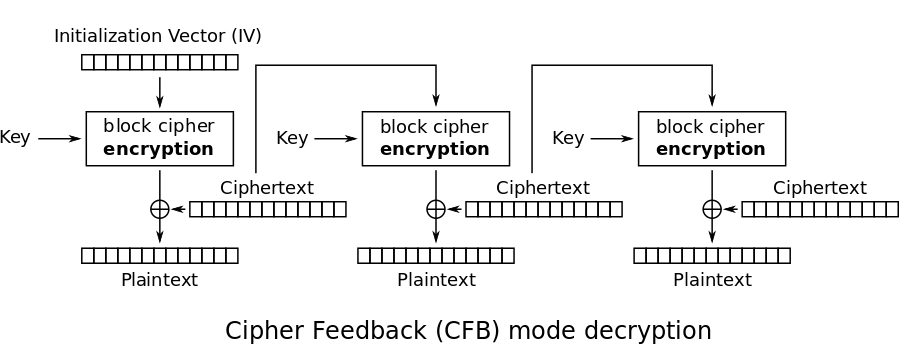
CFB
The circled plus sign is the XOR operation
CFB chains the encryption togeter, using the output of the last block’s ciphertext as part of the encryption for the next block. The first encryption step instead uses a randomly generated initialization vector which is just a fancy word for starting value. This should be shared together with the secret key to allow for decryption later on.
This is a lot more secure because patterns in the input will not be discernible from the output anymore. The downside is that errors in one of the encryption steps will propagate throughout the other blocks.
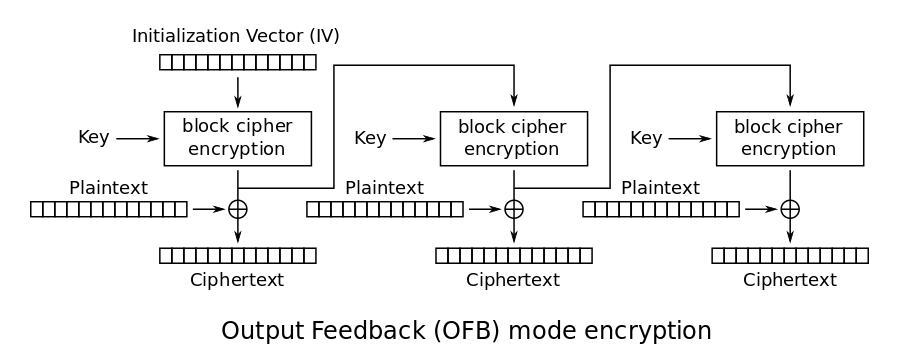
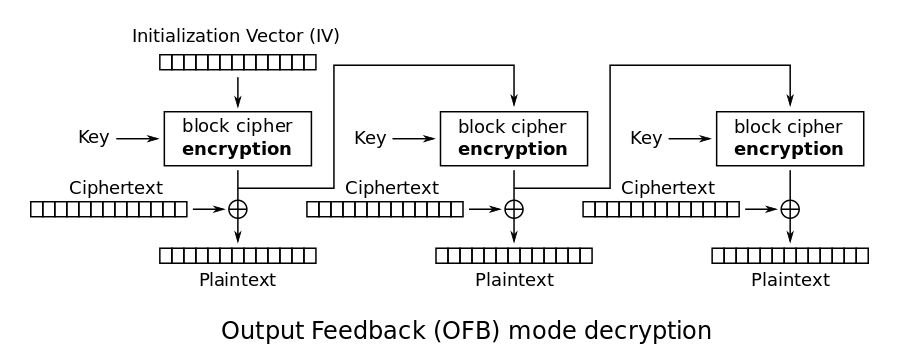
OFB
OFB is very similar to CFB in the way the chaining works, but the output of the encryption step is directly used in the next step without the XOR. This still requires has the advantage of being able to precompute the outputs of the encryption functions when you have the IV and key, and later run the XOR operations when you have the ciphertext which can be done in parallel (fast 🙂 ) The structure is also very resembling of a stream cipher.
RSA
RSA is one of the older and most common examples of asymetric cryptography. You can (should) read more about it here: https://en.wikipedia.org/wiki/RSA_(cryptosystem) Until i get the will to write down more about the math involved… (too many p’s and q’s floating around in my head)
Elliptic curve
This is a more modern approach to cryptography, but sadly also a lot harder to implement. Elliptic curve cryptography is used for example in ed25519 SSH keys. This post is often seen as a good introduction if you like math (or are just interested and have had enough coffee).
Some notes for myself written down publicly in the hopes that they might help some future person.
It is highly recommended to have the cluster on a vlan/vswitch! Galera does not implement it’s own security for the cluster ports. See the vlan part at the bottom of this document if you do not have vlans setup yet.
In this example the following IPs are used: Local machine: 192.168.100.1 Another cluster node: 192.168.100.2
If this is the first node in the cluster, or all nodes in the cluster are currently down, you have to run galera_new_cluster to bootstrap the cluster again. Otherwise you can just start the mariadb service through systemd.
Now you’re good to go! While everything should work now, if you want to read more about galera you can do so here.
Addendum: Vlans
You should keep the cluster on a vlan for security reasons. This can be done in netplan by editing /etc/netplan/(yourconfig).yaml and adding:
Mainly applicable to middle/high-school and smaller university classes. Depending on your country’s school system.
Minimize Distraction
preferably blur out windows at eye height when sitting. Having something going on outside can completely destroy how information flows, however good your teaching is. This is often not something you can do something about as a teacher. But you can try to pick a room with as least distraction as possible.
Have students take notes. The error that a lot of lecturers make is that they expect students to make notes by themselves, but if you start without a notebook in front of you you are in no way inclined to grab it when needed. Start the lecture with a short question “does everyone have their books in front of them?” and also give them some time to write down what you say. A subtle clue can also be to say that people to not have to write down x thing, implying that the rest must be written down.
Talking people are the death of any lecture. The best way to minimze this is to make sure you are well audible and also to show that you (and all other students) can hear it when a student is talking. Preferably have semi-small groups of no more than ~20 students or a room that is setup such that sound seems amplified, how counter-intuitive it may seem.
Minimize cutoff
Never, ever, have a slide full of text or even worse, equations to talk through. People will lose you, and probably wont catch on later either if you take too long. Break problems up into smaller sets, and preferably leave out duplicate information.
Give people a chance to jump back on after a while. Give people something to think about for a short time and then start a new part-subject. Make it obvious that you are restarting from scratch so people have a chance to get on.
Don’t be boring, but also not too hyper-active. A boring teacher will make his students bored, but a hyper-active teacher will probably also lose out on the energy of students really quickly. A teacher that likes their area is way more likely to generate interested students than one who seems to be bored. (if the teacher is bored then why would you ever want to learn more about it)
Be sure of what you are saying. If you have to think a long time of what you are doing people will quickly lose trust, start talking about it, and dropping off.
Mainly for math subjects: You do not have to rigorously prove complicated things in your lectures. Students don’t care and they sure as hell don’t have the time to take it all in during the 1 minute that you have your slide up. Students really like to know “why” something is true, but giving intuition is often a thousand times better than plomping down a complicated formula and just reading that off of the slides.
Similar to last point. Don’t just show definitions. Show examples. A student cannot remember all your definitions, but they will remember examples. If needed show them many edgecases that implicitly or explicitly explain the definition.
Again mainly for math: Where possible, use a blackboard or even digital drawing instead of slides. It is extremely important for students to grasp the steps of solving a problem, and doing it step by step allows you to explain your reasons, allows asking more specific questions from students, and better overall intuition. Blackboards are a lot of work, but what works similarly well is a drawing tablet projected on a screen. You don’t have to lose time and focus when clearing out the board, can go back to show how something correlates to a previous assignment, and share the results for later reference. Do make sure that you have a cheatsheet next to you so you don’t make any big mistakes. Or do and show how students can check themselves when they are solving problems.
Lectures often build on eachother, but may be spread out. If you are handling a lot of information in a single lecture then it’s a good idea to have recitations after a day or two to help students remember.
Optimizing tests
Tests are not for teaching, please do not include too much new information that might confuse students. Application of the actual course content is of course fine or even imperative.
Give everyone their test back after they are graded. Show people where they made errors even if they do not want to redo it. Tests often give a great amount of different topics to see what you know, and re-reading a test is a great way to see what errors you made and where your ideas might differ from the teacher’s. (notationwise, etc). Don’t have students go somewhere to view their test or have them wait a long time. Stimulate them to actually take their time and take away any barriers.
Offer a demo-test. This is a great way to prepare students so they have a nice checklist of what to learn and a way to test this. If you think most of your students aren’t making the demo-test include one of the demo-test questions on the real test. This will give them a good reason to use the demo-test when learning and will greatly improve their grades. (don’t re-use more questions, don’t be that guy)
Make sure students have enough time. Your goal is to check if the student knows what you told them. Not how fast they can read and write
Use a lesson to talk through items of the last test that didn’t go well, and add a small question on the next test with that same item for a couple of points. If you have no reason to want them to still learn it then why were you testing them in the first place?
If you have no reason to want them to still learn it then why were you testing them in the first place?
(Math) Textbooks
Structuri_Algebrice_in_Informatica
The following example is taken from a friend’s mathematical textbook, but any student who has done math at a decent level will recognize the kind of text. It being in romanian only helps prove the point.
Mixing math and normal language is funest for learning. Take mixing french and german in a text. You can’t read it easily even if you know both languages. Let alone remember the content. For most humans, the language processor cannot switch between such different languages efficiently enough (though i’m not aware of any scientific research on this). Books like this want to be mathematically rigorous, but end up being completely useless. If you look at for example MIT’s mathematics for CS book and this the difference is as day and night. MIT has formulas cleanly separated and focussed on their relation in written text, while other books often have this mixmatch of inline unreadable math that makes most people want to stop reading and just watch youtube videos instead.
Asking questions
This is something that many education systems struggle with, and it’s almost become a culture thing in a lot of countries.
Educators often ask themselves why students are not asking questions. Even though it’s obvious from the next test that they didn’t understand everything well. And it’s a sad by-product of mass education.
The amount of questions asked is often already decided in the first lecture by the speed and thoroughness of which an educator anwsers it. If a student has to wait a long time and the subject has already passed, the student (and for one question-asker many others) will already have missed the point, and having to go back feels like you are wasting everyone’s time.
If an explanation is too short, the student might not understand yet or feel dumb, which will stop them from asking more questions. If the explanation is too long the other students will quickly get distracted or the student will feel like it’s a waste of time. Try to keep your answers to questions to the global audience and make them part of your lecture, don’t just look the specific person in the eye and talk softly to them as you will surely lose all other students. The trick here is to gauge what level of understanding all students are on, but this is an extremely hard if not impossible task.
What my university did very well was create a discord group with specific channels for each subject for asking questions. Being able to ask them semi-anonymously (under your real name, but no face) helps a lot with getting people to ask questions, and you have a lot more tools like a LaTeX bot or images. It would help if there was a bit more of a culture of also anwsering those questions. Perhaps by having TA’s anwser some of them, but this fills a very important gap. Somes universities have specific question-hours but these are often not very productive as people are not actively working on the content at those moments. It’s better to allow asking these questions when people are working on the content at school or at home.